Exchange Server 2013 can be installed on either Windows Server 2008 R2 or Windows Server 2012.
Some organizations may decide to install on Windows Server 2008 R2 because that is their standard server build and to remain consistent with the rest of their server fleet. However, doing that will mean they miss out on the new features of Windows Server 2012.
One of those new features is a cluster quorum management option known as dynamic quorum.
As TechNet explains:
When this option is enabled, the cluster dynamically manages the vote assignment to nodes, based on the state of each node. Votes are automatically removed from nodes that leave active cluster membership, and a vote is automatically assigned when a node rejoins the cluster.
With dynamic quorum management, it is also possible for a cluster to run on the last surviving cluster node. By dynamically adjusting the quorum majority requirement, the cluster can sustain sequential node shutdowns to a single node.
In an Exchange context, dynamic quorum can make database availability groups more resilient to multiple node failures.
To demonstrate this, here is what happens to an Exchange Server 2010 DAG when it suffers multiple node failures.
To begin with the DAG is healthy and all nodes and resources are online.
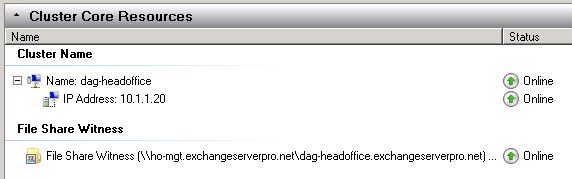
[PS] C:\>Get-Cluster | Get-ClusterNode Name State ---- ----- ho-ex2010-mb1 Up ho-ex2010-mb2 Up [PS] C:\>Get-MailboxDatabase | Test-MAPIConnectivity MailboxServer Database Result Error ------------- -------- ------ ----- HO-EX2010-MB1 MB-HO-01 Success HO-EX2010-MB1 MB-HO-02 Success BR-EX2010-MB MB-BR-01 Success HO-EX2010-MB1 MB-HO-03 Success HO-EX2010-PF MB-HO-Archive Success
Next, I take down the file share witness, and then a short time later one of the DAG members as well.

[PS] C:\>Get-Cluster | Get-ClusterNode Name State ---- ----- ho-ex2010-mb1 Up ho-ex2010-mb2 Down
After a few moments the cluster determines that quorum has been lost, and the remaining node stops as well.
Log Name: System
Source: Microsoft-Windows-FailoverClustering
Date: 5/27/2013 8:12:22 PM
Event ID: 1177
Task Category: Quorum Manager
Level: Critical
Keywords:
User: SYSTEM
Computer: HO-EX2010-MB1.exchangeserverpro.net
Description:
The Cluster service is shutting down because quorum was lost. This could be due to the loss of network connectivity between some or all nodes in the cluster, or a failover of the witness disk.
The entire cluster is now down, taking the mailbox databases with it, even though a single DAG member was still online.
[PS] C:\>Get-MailboxDatabase | Test-MAPIConnectivity MailboxServer Database Result Error ------------- -------- ------ ----- HO-EX2010-MB1 MB-HO-01 *FAILURE* Database is dismounted. HO-EX2010-MB1 MB-HO-02 *FAILURE* Database is dismounted. BR-EX2010-MB MB-BR-01 Success HO-EX2010-MB1 MB-HO-03 *FAILURE* Database is dismounted. HO-EX2010-PF MB-HO-Archive Success
Now let’s take a look at what happens to an Exchange 2013 DAG running on Windows Server 2012 with dynamic quorum enabled (which is the default setting). This Exchange 2013 DAG in my lab happens to have more Mailbox servers as members than my Exchange 2010 DAG, but that does not impact the demonstration.
Again, to begin with the cluster resources are all healthy and online.
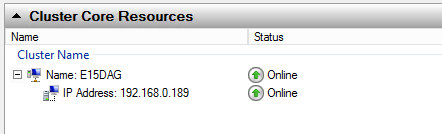
[PS] C:\>Get-MailboxDatabase | Test-MAPIConnectivity Creating a new session for implicit remoting of "Get- MailboxServer Database Result Error ------------- -------- ------ ----- E15MB1 Mailbox Database 1 Success E15MB1 Mailbox Database 2 Success [PS] C:\>Get-Cluster | Get-ClusterNode | Select Name,DynamicWeight,NodeWeight,Id,State Name DynamicWeight NodeWeight Id State ---- ------------- ---------- -- ----- E15MB1 1 1 1 Up E15MB2 1 1 2 Up E15MB3 1 1 3 Up
Each node currently has 1 vote (shown as DynamicWeight in the output above). Two of three votes (a majority) is required to achieve quorum, which the cluster has.
First I’ll shut down one of the DAG members. Now let’s take another look at the nodes.
[PS] C:\>Get-Cluster | Get-ClusterNode | Select Name,DynamicWeight,NodeWeight,Id,State Name DynamicWeight NodeWeight Id State ---- ------------- ---------- -- ----- E15MB1 0 1 1 Up E15MB2 1 1 2 Up E15MB3 0 1 3 Down
As this article explains, dynamic quorum kicks in and removes the vote from one of the remaining cluster nodes. Now only one node has a vote, and quorum is maintained.
If this were a Windows Server 2008 R2 cluster quorum would also be maintained, however the difference is in what happens on the next node failure.
Next I take down another DAG member. With one remaining DAG member the Exchange 2010 cluster and databases went offline. However the Exchange 2013 DAG stays online thanks to dynamic quorum.
[PS] C:\>Get-Cluster | Get-ClusterNode | Select Name,DynamicWeight,NodeWeight,Id,State Name DynamicWeight NodeWeight Id State ---- ------------- ---------- -- ----- E15MB1 1 1 1 Up E15MB2 0 1 2 Down E15MB3 0 1 3 Down [PS] C:\>Get-MailboxDatabase | Test-MAPIConnectivity MailboxServer Database Result Error ------------- -------- ------ ----- E15MB1 Mailbox Database 1 Success E15MB1 Mailbox Database 2 Success
While this is only a simple demonstration it does show the potential of dynamic quorum for making Exchange 2013 database availability groups more resilient.
Although there are other failure scenarios that may still cause the DAG to go offline (eg multiple simultaneous server failures), with the right cluster design and operational procedures for managing the cluster you can achieve a good outcome.
For more on dynamic quorum in Windows Server 2012:



Hello Paul,
Thanks for the article. I have two questions.
1- Is Dynamic Quorum required in a DAG environment with three nodes one of which is located at a DR site?
2- Is there a Witness Server requirement both in Prod. and DR. sites in such a scenario?
As this article explains, dynamic quorum kicks in and removes the vote from one of the remaining cluster nodes. Now only one node has a vote, and quorum is maintained.
=> the hyperlink of the article is dead, can you explain again to me :), im confused about that.
https://docs.microsoft.com/en-us/windows-server/storage/storage-spaces/understand-quorum
-> i read the topic, i think in the situation, 2/3 active node will remain 1 vote.
Howdy very nice website!! Guy .. Beautiful .. Wonderful ..
I’ll bookmark your web site and take the feeds additionally?
I’m happy to seek out numerous useful information here in the submit, we need work out more techniques
on this regard, thank you for sharing. . . . . .
Hello Paul
Thank you for your reply.
I have the test environment both at work and my home and this has never worked for me.
So let this be my last question.
If the DAG is configured properly, and if all the server besides the server with lagged db is down, the logs will be replayed to the lagged db automatically and would eventually activate.
Am I correct?
This actually has never occured in the prod environment , but in such situation, I was always wondering if we should switch the environment to the DR site or not.
The Real Person!
Author Paul Cunningham acts as a real person and passed all tests against spambots. Anti-Spam by CleanTalk.
What I can say is that I have activated lagged database copies successfully in the past.
I don’t know if I have done it under those specific circumstances before. It should be possible, but there may be something missing or misconfigured that is causing it to fail.
If you’re talking about doing a full DR datacenter switchover, you should refer to the datacenter switchover documentation as well to see whether you need to add that to your overall process.
Yes, got an error message.
Its not in english, so I cannot fully reproduce, but it says something like “It couldn`t reach the active manager on the server that has the active DB..”
The Real Person!
Author Paul Cunningham acts as a real person and passed all tests against spambots. Anti-Spam by CleanTalk.
Since I can’t see your environment, the exact commands you’re running, and the exact error message, there’s not much more I can suggest. Review the event logs for clues, or open a support case with Microsoft. Perhaps there is some other configuration issue with the DAG preventing the lagged copy activation from working.
Hi Paul
I manage 3 exchange servers with 2 servers having DB with replaylagtime 0 and 1 server with replaylagtime 14 days. With dynamic quorum, it is possible for the cluster to be up and running even if two servers go down, but if the remaining server is the server with lagged DB, the DB cannot activate on this server and the status of the DB becomes disconnected. Is there anyway to activate the laggged DB in this situation and keeping the service to the user.
The Real Person!
Author Paul Cunningham acts as a real person and passed all tests against spambots. Anti-Spam by CleanTalk.
Yes, you can activate a lagged database copy. TechNet has the procedure here.
https://technet.microsoft.com/en-us/library/dd979786%28v=exchg.160%29.aspx
Hello Paul
Thank you for your reply.
Yes, I know there is a way to activate the lagged db with some options, but that is possible if the active server is up and running. My question is if all the serve besides the server with replaylagtime is down, how is it possible for the lagged DB to be activated on the server. seems like the move-activatemailbox command doesn`t work in this case since the server that holds the DB is shutdown..
The Real Person!
Author Paul Cunningham acts as a real person and passed all tests against spambots. Anti-Spam by CleanTalk.
Every server in the DAG that hosts a copy of the database has its own copy of the database files and logs. During a switchover, failover, or activation of the lagged copy, the server will use its own copy of the files. There is no requirement for any other DAG member to be available.
If this scenario is a concern for you then I recommend you build up a test environment and simulate the failure situation that you want to know how to respond to, and practice the procedure for activating the lagged copy.
Hello Paul
Thank you for your reply again.
Yes, I have already tested with the similar test environment.
I had shutdown two exchange server that holds DB with replaylagtime 0 (one with active DB), and there is only one exchange server left with replaylagtime of 14 days. In this situation, I expected that the log would be replayed to the DB and would eventually activate. But the result was that the status of the DB of the remaining server was disconnected and the replayqueuelength of the DB did not decrease and stayed the same. Also move-activemailboxdatabase command did not work as well.
The Real Person!
Author Paul Cunningham acts as a real person and passed all tests against spambots. Anti-Spam by CleanTalk.
What does “did not work” mean? You got an error message?
Pingback: Alternative Witness Server for Exchange 2013 DAG – A random blog from a sysadmin
hi Paul.
I can use a CSV Volume for a Disk witness for my cluster? for a Exchange DAG.
Thanks
The Real Person!
Author Paul Cunningham acts as a real person and passed all tests against spambots. Anti-Spam by CleanTalk.
I don’t think I’ve ever seen it called out as a supported or unsupported option. I suspect it may be unsupported. At the very least it is unnecessary and provides no actual benefits. A simple file share is all that is required.
Just so i get this setup correct.
I have 4 – Exchange 2013 Sp1 latest CU on 2012 R2 in an IP-less DAG, split 2 servers at 2 sites with a an FSW at a 3rd site.
Taking the FSW down does not harm the DAG, correct?
And if my math is correct with dynamic quorum, i can lose 1 site (2 servers) and still be up, can i also lose the FSW and still be up as well? or is 2 servers my limit?
The Real Person!
Author Paul Cunningham acts as a real person and passed all tests against spambots. Anti-Spam by CleanTalk.
If a failure occurs and the cluster is able to maintain quorum, dynamic quorum can adjust the quorum requirement so that the cluster is more resilient to the next failure. If a failure occurs that results in quorum being lost, dynamic quorum won’t be able to help.
Paul,
This is an OUTSTANDING article!
I currently have my exchange environment configured with 2 Exchange 2013 Servers both running on Windows Server 2012 R2 and a file share witness. It is possible to reconfigure the DAG to NOT have a FSW and use only dynamic-quroum? Will this break my current environment if I change it on the fly?
Also I still have a couple of legacy exchange servers in another environment that I have not yet removed/decommissioned. I have migrated everyone to the new Exchange 2013 Severs which are running on Server 2012R2 with a FSW. Can I do the same with no impact?
Hello, I can build a resistance environment with two mailbox servers one for each site
Pingback: Exchange Server 2016 Database Availability Groups
Hello Paul,
I have a question regarding Windows 2012 Failover clustering.
We have Windows 2012 running with Exchange 2013 DAG. 8 nodes 1 witness server.
Nodes are running on VMWare servers.
There are few instances where one of the nodes lost the quorum due to network issues. When ever that happens cluster service goes in restarting (crashing). I tried to change Cluster service to manual and then start it but, it just keep crashing until I restart the server after that it works fine that node once again gets added into the quorum without any issues.
My question – Is it normal behavior if node lose the quorum cluster service keep restarting until you restart the server? Or is there any way to bring back that server in the quorum without restart of the server.
clussvc.exe version 6.2.9200.21268
Error
The Cluster Service service terminated unexpectedly. It has done this 15 time(s). The following corrective action will be taken in 60000 milliseconds: Restart the service.
Thanks,
Nevermind, I got it now. You can delete that last question. You already answered it, sorry.
So as long as the A record for email.domain.com does not point to the DR server then clients will not use it correct?
So just have a single namespace and leave the A record out for the DR cas/mbx server and add it back only in the event that my two dag members are down at production? Do I got that right?
The Real Person!
Author Paul Cunningham acts as a real person and passed all tests against spambots. Anti-Spam by CleanTalk.
Yes, the DNS change to DR is part of your manual datacenter switchover process.
So if I had a single namespace, could there be a potential for clients to use the CAS at the DR site? The reason I want to control is that I’m hoping the only time we have to fail over is if there was a site outage. The link between the two sites has a lot of traffic and the servers/storage at the DR site are not as robust as production. So if it happened to be just an issue with both exchange servers on site, id like to be able to make that decision to failover before I end up with 400 clients accessing exchange on a slow link. That way I can determine if its something I can fix quickly and bring online again. If I fail over and then fix the issue, my clients have to continue to access their mailboxes at the DR site until the databases reseed. Does that make sense? I like the single namespace idea, sounds like I have to make dns changes either way. Adding a A record for email.domain.com for the DR server if it goes down, or change the autodiscover CNAME record to point to emaildr.domain.com if I stick with two namespaces. Do you agree with my logic?
The Real Person!
Author Paul Cunningham acts as a real person and passed all tests against spambots. Anti-Spam by CleanTalk.
“So if I had a single namespace, could there be a potential for clients to use the CAS at the DR site?”
You have 100% control via DNS where your Exchange namespaces resolve to.
The rest of your comment seems to be based around uncertainty on that one point.
Paul,
I never want to have the DAG automatically fail over to the DR site if that helps, so if the clients are not able to automatically detect the other namespace once I manually activated the DBs at the DR site, am I better off with one namespace but exclude an A record for the IP of the DR server pointing to email.domain.com and manually add this in the event of a site failover. Just trying to see what is the best option.
Dave
The Real Person!
Author Paul Cunningham acts as a real person and passed all tests against spambots. Anti-Spam by CleanTalk.
One namespace is simpler. You can use DNS to control where that resolves to, and manually change it over to the DR site in such an event.
Similarly you can block database copy activation on the DR DAG member to prevent databases from automatically failing over to that site.
Separate AD and Exchange namespace is fine. Quite normal.
Autodiscover only cares about Exchange namespaces (email addresses really).
Just remember, the more you try to block and prevent certain behaviors (eg clients connecting to a CAS at a different site, databases activating at a secondary site) the more complex your configuration becomes, the less resilient it becomes (because you’re excluding servers from participating in automatic failovers), and the more steps required for manual switchovers.
Paul,
I’m trying to wrap my head around what type of namespace model I should use. All of my mailbox users are connected to one datacenter, where I’ll be using email.domain.com. We have a DR site in case our main site is down and I was using emaildr.domain.com. In the event that this would happen and my users had to log onto Citrix servers at the DR site to work, or even connect to OWA or activesync, they are going to have to be directed to use emaildr.domain.com and change their smartphones to point to the right address. Now once they log onto Citrix and our AD domain, how will the Outlook client know to connect to emaildr.domain.com if the autodiscover.domain.com is a CNAME pointing to email.domain.com?
Having just a single namespace poses a problem too because I plan to use DNS RR and I don’t want to include a third A record for email.domain.com to point to the CAS at the DR site and have users proxying through the CAS and back to their mailbox over a WAN link. What would you recommend?
I don’t know if it matters, but I should point out that our AD domain and our email domain differ. For the purpose of this question, lets say our AD domain is addomain.com and our email domain is domain.com. Right now I have an autodiscover CNAME for both AD and email domain and they point to the A record of email.domain.com. Still running Exchange 2007 but am implementing co-existence this weekend. I have two 2013 CAS/MBX server at production site and one CAS/MBX server at DR site all in a DAG.
Thanks again for your input. Your articles have been very helpful
Dave
In your lab scenario, if only two nodes out of three remain online and the network between node 1 and 2 fail but the nodes are still online, wouldn’t this cause split brain?
I would expect Dynamic Quorum to only allow one of the two to survive and retain quorum, the other should go offline.
Sounds like I should just leave it the way it is. I think I’d rather have a manual failover to my DR site anyway, wouldn’t you agree? Everything else that we replicate to our DR site is set to manual failover.
For Exchange 2007, my namespace at the DR site is emaildr.domain.com. I’m hoping that I won’t have to failover during co-existence (highly unlikely), do you think it’s necessary for me to have a legacydr.domain.com for my Exchange CAS at the DR site, or should I just leave it as is and make my 2013 CAS at the DR site emaildr.domain.com too and just leave DNS pointed as is for the time being and modify and point to the 2013 CAS server if I had to failover. Or should I change the 2007 namespace to legacydr.domain.com? I don’t know if I’ll bother updating my SAN certificate to include legacydr.domain.com. Worst case is that they’d get a certificate warning until I had to update my cert for a DR scenario. Your thought?
Thanks for your input. BTW, I tested DNS RR today with my multi-role servers and it worked great. I had the TTL set to 5 minutes. I tested it twice; one time shutting down the server with the active DBs and the other time I just disconnected the NICs. The Outlook client restored connection to Exchange around 2 minutes the first test and a little over a minute on the second test.
I still plan to implement a load balancer in the future after my budget it approved. I was looking at the Kemp appliances, but now am leaning toward the Citrix Netscaler appliance. We need one for added security for remote access to our Xenapp farm and we can also use it to load balance our web servers and provide reverse proxy/LB for Exchange as well.
The Real Person!
Author Paul Cunningham acts as a real person and passed all tests against spambots. Anti-Spam by CleanTalk.
It’s hard to give advice with limited knowledge of a specific environment. It sounds to me like either legacy namespace approach could work. Always include all the namespaces on SSL certs, though, don’t leave any off.
Paul,
In my Exchange 2013 DAG I plan to have two multi-role servers and a file share witness in my production datacenter and one multi-role server in my DR site (they are separate AD sites as well). If I were to experience an unexpected site outage at my production site, would dynamic quorum still be able to keep the DAG online? A production site outage would definitely cause multiple simultaneous server failures so I’m assuming it wouldn’t. If that’s the case, would you agree that I place another Exchange server at my DR site? The drawback is that it’s more costly storage needed and hopefully it will never be used. Or should I have made one of my servers at the DR site my file share witness instead of at the production site? That seems more logical now. Thanks for your input.
Dave
The Real Person!
Author Paul Cunningham acts as a real person and passed all tests against spambots. Anti-Spam by CleanTalk.
Dynamic Quorum is unlikely to help in any major or simultaneous/multiple server failure.
Also, for automatic site failover like you’re describing, the FSW needs to be in a third datacenter that is connected independently to both other datacenters, so that quorum can still be achieved (which also implies that the DAG has the same number of nodes in both datacenters).
Putting the FSW at the DR site won’t help you either, in fact that will cause more outages if there’s a WAN failure because neither site can achieve quorum. The FSW should always be placed in the site you consider the “primary”, or a third site.
Without meeting all the requirements for automatic site failover you can expect a failure of your primary datacenter to take the DAG offline, and require a manual datacenter switchover.
Could this not be resolved by specifying an alternate FSW at the DR site?
The Real Person!
Author Paul Cunningham acts as a real person and passed all tests against spambots. Anti-Spam by CleanTalk.
The alternate FSW is only used in manual datacenter switchover scenarios. It isn’t part of the quorum voting process.
Is the use of the dynamic quorum model officially supported? I cannot find any kind of statement about this in the Exchange 2013 TechNet library.
The Real Person!
Author Paul Cunningham acts as a real person and passed all tests against spambots. Anti-Spam by CleanTalk.
Good question. Yes it is supported, though I can’t find a specific mention of that on TechNet. So here is the next best thing, the EXL322 session slides from TechEd Australia 2013 spell out the situation with DAGs and Dynamic Quorum nice and clearly.
http://video.ch9.ms/sessions/teched/au/2013/EXL322.pptx
“- Dynamic quorum does not change quorum requirements for DAGs
– Dynamic quorum does work with DAGs
– All internal DAG testing is performed with dynamic quorum enabled
– Dynamic quorum is enabled in Office 365 for DAG members on Windows Server 2012
– Exchange is not dynamic quorum-aware
Exchange team guidance on dynamic quorum:
– Leave it enabled for majority of DAG members
– Don’t factor it into availability plans
The advantage is that, in some cases where 2008 R2 would have lost quorum, 2012 can maintain quorum; this only applies to a few cases, and should not be relied upon when planning a DAG”
Pingback: Exchange Server 2013 Database Availability Groups
Hi paul ,
Please clarify some of my doubts regarding dynamic quorum configuration in exchange 2013 dag .
In my lab environment i have two mailboxservers in exchange 2013 dag and i had kept my file share witness in my cas server .Both the mailboxservers and cas server are in the same ad site.
To test the dynamic quorum ,first i had shutdown my file share witness and then i had shutdown my mailbox server (which is holding passive database copies) with two minutes gap.
After that i went and checked the server which is holding the active database copies it shows all the databases are in mounted state and I felt happy about dynamic quorum role .But aftersometime all of the sudden it shows all the databases are in dismounted state . i dod’nt know what i had done wrong ?
Paul,
I have exactly the same issue.
One DAG with 2 nodes and 1 FSW. If I shutdown one node or the FSW the DAG is up and running. When I shutdown a 2nd system (FSW or a node) and still have 1 node up, the DAG will fail.
Even when I shutdown a node and check the DynamicWeight it doesn’t change.
Do you have clue what might be wrong?
You should always monitor which server is going down. There is no reason what so ever to shut down the FSW, ever and ever. Dynamic Quorum needs an FSW to work. If there is ONE Exchange MB servers going down and an even number of Exchange MB servers is still running one of them will lock the FSW. When an odd number of Exchange MB servers is still running the FSW will loose(!) its function (temporarily). When the next Exchange MB server goes down, (even number of Exchange MB servers stay up) the FSW will get its function back and one of the remaining Exchange MB servers will lock this FSW. (The 2010 Example does not really explain what happens)
FSW is never ment to be handled manually.
(You could also create an alternative secondary FSW, which will kick in when the first FSW should fail)
The real(!) dynamic vote is the FSW. So never shut it down, and replace it when it is unavailable by hardware failure.
The Real Person!
Author Paul Cunningham acts as a real person and passed all tests against spambots. Anti-Spam by CleanTalk.
A strange comment there Bart, and almost entirely incorrect. The FSW is a server like any other. You need to patch the operating system, which will mean restarting it. You can also shut it down without harming the DAG, as long as quorum is maintained. The alt FSW doesn’t kick in when the FSW fails.
I have the exact same issue. dynamic quorum does not do what it is supposed to in the real world. dont depend on it!
Hi Paul,
Great article, I know I wasn’t loosing my mind when testing this in my Exchange 2013/ Windows Server 2012 POC. Everything/one was telling me I should be loosing quorum when testing the “last man standing” concept. I can now confidently explain why we don’t and we can sustain multiple node failures in a 4 member DAG with 1 FSW!
Ryan
Thanks Paul
really interesting
I missed that server 2012 feature somehow:)